day 16 (스압)

Plotly(day15 ~ 16)
시각화의 3요소 : 데이터(값), x축, y축
데이터에 어떤 그래프가 적절할 지 안목을 기르는 것이 중요하다. 분석 목적과 데이터 형태에 따라 적절한 그래프가 있는데, 꾸준히 연습하면서 감각을 키워야 한다. 시각화에 대한 기본적인 이해를 바탕으로 도구를 활용해야 한다. method의 옵션은 외울 필요가 없다. 다만 Docstring을 보며 그래프를 어떻게 바꿀지 생각하면서 어떤 파라미터를 사용할 수 있을지 고민해야 한다.
1) 장점
-인터렉티브한 시각화
-한글설정 필요가 없다!!!
-인터페이스만 파이썬이고 내부는 자바스크립트라 빠르다
-증권 관련 시각화뿐만 아니라 비즈니스 관련 시각화도 미려하게 제공한다
2) Plotly Express: high-level interface for data visualization
-사용이 훨씬 쉽고 간편(추천)
-그러나 커스터마이징에 한계가 있고 다른 라이브러리 의존적이어서 버전 호환성 문제가 발생할 수 있다
3) Graph Objects: low-level interface to figures, traces and layout
-다양하고 정교한 시각화가 가능하다
-코드가 훨씬 길고 복잡하다
import plotly
import plotly.express as px
일별 수익률 그래프 그리기
1) 선그래프
px.line(df, x='date', y='GOOG', title='일별 시세')
# px.line() plotly 라이브러리의 lineplot
# df 시각화할 데이터 변수명
# x축, y축 변수 지정 (Docstring으로 다양한 매개변수 지정 가능)px.line(amd.iloc[:,:4])
# iloc[ : , : 4] 전체 행 데이터를 가져오는데 4개 컬럼의 값을 가져와라
▼Plotly API
px.line(df.set_index("date"))
# 'date'를 인덱스로 설정하여(x축 지정) lineplot을 그려라
▼Pandas API
df.set_index('date').plot()
# date컬럼을 인덱스로 설정하여(x축으로 지정) plot을 그려라
2) 막대그래프
df_1 = df.set_index('date') - 1
"""
'date'컬럼을 인덱스로 지정한 데이터 프레임에서 1을 뺀다(기준이 되는 첫 날의 값이 1이고
나머지 날짜는 첫 날을 기준으로 하기 때문에 1을 빼면 0값을 기준으로 수익률을 알 수 있다
"""
▼Plotly API
#방법1
px.bar(df_1, x=df_1.index, y='FB')
#방법2
px.bar(df_1, y='FB') #y축만 지정해도 가능(df_1 인덱스 지정으로 x축 변수가 이미 정해짐)
#방법3
px.bar(df_1['FB']) #가장 간단한 코드
#참고
px.bar(df_1, ['FB'])
#콤마(,)를 넣으면 그래프가 horizontal하게 그려진다
#인구통계표에 때 주로 사용
▼Pandas API
df_1['FB'].plot(kind='bar', figsize=(10,2))
facet_col로 subplot 그리기
1. 서브플롯으로 그리고자 하는 값을 지정해준다
df_1.columns.name = 'company'
# .columns df의 컬럼명, dtype을 알려준다
# .name 서브플롯으로 그리고자 하는 값 지정하게 하는 메서드
2. 시각화한다
px.area(df_1, facet_col='company', facet_col_wrap=2)
# px.area 라인과 0축 사이 영역을 채워서 보여주는 그래프
# facet_col 서브플롯 기준 지정
# facet_col_wrap 한 줄에 넣을 그래프 개수 지정
여러 종목을 하나의 그래프로 시각화
px.line(df, hover_data={"date": "|%Y-%m-%d"})
# df_1로 실행하면 오류가 난다 : 인덱스로 접근해야 한다
# hover_data={"date": "|%Y-%m-%d"} 커서를 그래프 위에 놨을 때 YYYY-MM-DD 형태로 시간을 나타내준다
px.line(df, x='date',y='GOOG', hover_data={"date": "|%Y-%m-%d"})
# y축을 지정하여 특정 데이터만 시각화할 수도 있다
Range Slider와 시계열 그래프
fig = px.line(df_1['FB'])
fig.update_xaxes(rangeslider_visible=True) #range slider 시각화
# rangeslider_visible=False 자동으로 rangeslider가 나오는 plot들이 있는데 =False 로 제거할 수 있다
Candlestick(캔들 차트)
주식을 비롯한 유가증권과 파생상품, 환율의 가격 움직임을 보여주는 금융 차트
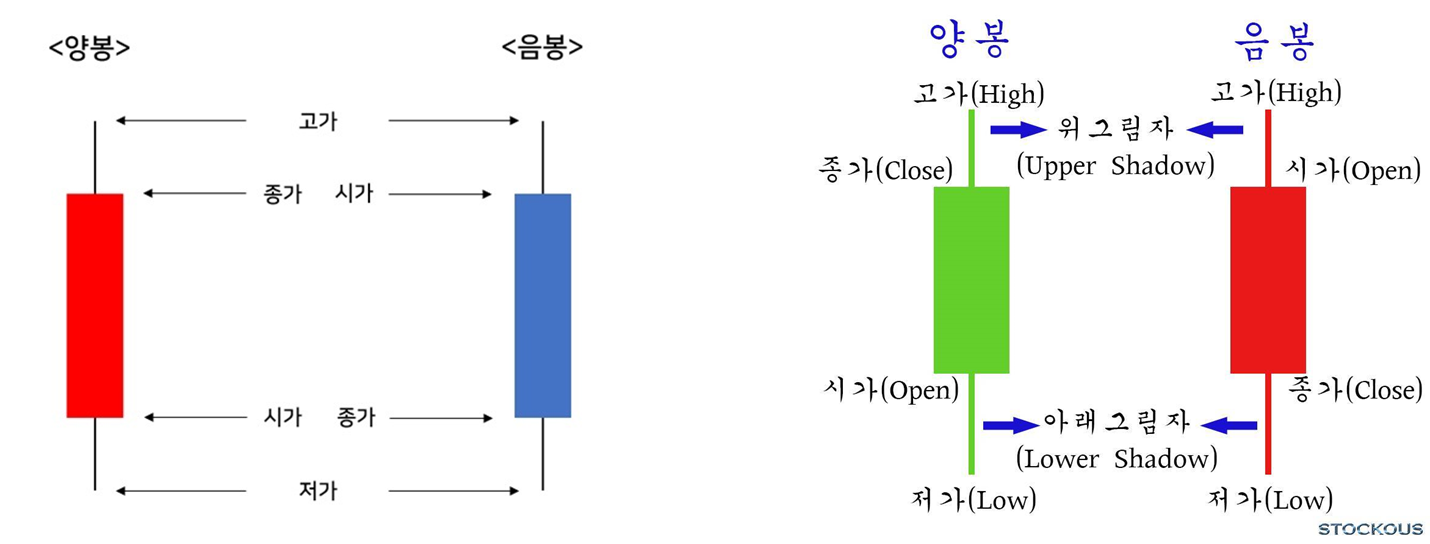
-"캔들스틱" 또는 "봉"은 일반적으로 "하루"의 가격 움직임을 나타낸다
import plotly.graph_objects as go # plotly objects 임포트
fig = go.Figure(data=[go.Candlestick(x=df['Date'],
open=df['Open'],
high=df['High'],
low=df['Low'],
close=df['Close'])])
fig.show()
OHLC(Open-High-Low-Close)
시간 경과에 따른 금융상품의 가격 변동을 나타내기 위해 사용되는 차트

fig = go.Figure(data=[go.Ohlc(x=df['Date'],
open=df['Open'],
high=df['High'],
low=df['Low'],
close=df['Close'])])
fig.show()
히스토그램
표로 되어 있는 도수 분포를 정보 그림으로 나타낸 것. 연속형 변수의 분포 형태를 막대로 보여준다.
px.histogram(amd['Change'],marginal="box", nbins=50)
# marginal="box" 주변 분포(marginal distribution, 부분 집합에 속한 확률 변수들의 확률 분포)를 boxplot으로 그려라
# marginal='rug' 도 있다
scatterplot
px.scatter(df_ratio, facet_col='company', facet_col_wrap=1, height=500)
# company마다 scatterplot 시각화
px.scatter(df_ratio, x='GOOGL', y="AAPL")
# 두 변수 간 관계를 볼 수 있다
px.scatter(df_ratio, x='GOOGL', y="AAPL", marginal_x='box', marginal_y="violin")
#두 변수 간 관계와 각각의 주변 분포를 볼 수 있다
distribution
px.box(df_ratio, color='company')
# company별 박스플롯
px.box(df_ratio, color='company', notched=True)
# notched=True 박스 모양 변화
px.box(df_ratio, color='company', notched=True, points='all')
# points='all' 모든 점을 박스플롯 바깥에 찍어서 보여준다(데이터 분포를 알 수 있음)
px.violin(df_ratio, color='company')
# 바이올린 플롯
px.strip(df_ratio, color='company')
# 스트립 플롯(점)<0303>
unique와 nunique, value_counts
고유값(유일값)에 관한 method
| unique() | nunique() |
| 고유값 종류 반환 | 고유값 개수 반환 |
| Series | DataFrame, Series |
1. unique()
데이터의 컬럼에서 고유값들의 종류를 리스트 형태로 출력
-고유값을 모두 반환한다
-Series에서만 사용이 가능하다
df['item'].unique()
# 'item'컬럼의 고유값 목록을 모두 반환하라
2. nunique()
데이터가 보유한 고유값 목록의 총 개수 출력
-DataFrame, Series에서 모두 사용이 가능하다
df['item'].nunique()
# 'item'컬럼에서 고유값 목록의 개수를 반환하라
3. value_counts()
데이터가 보유한 고유값 목록별 개수 출력
-내림차순 정렬이 디폴트, ascending=True로 오름차순 정렬을 지정할 수 있다
df['item'].value_counts()
# item의 각 고유값 항목별 개수를 반환하라
df['item'].value_counts(ascending=True)
# item의 각 고유값 항목별 개수를 오름차순으로 반환하라
# 특정 컬럼의 비율 구하기
df['연도'].value_counts(normalize=True)
# normalize=True 정규화 조치. 비율 합을 1로 만들어 각 고유값 항목별 비율을 반환한다
#특정 컬럼의 비율 백분위로 구하기
df['연도'].value_counts(normalize=True) * 100
astype(str)과 str()
데이터를 문자열로 형 변환하는 함수
1. astype(str)
Pandas문법 사용
df["연도월"] = df['연도'].astype(str)+'-'+df['월'].astype(str)
# '연도' 컬럼과 '월'컬럼의 값을 문자열로 자료형 변환
# 문자열끼리는 + 로 연결해줄 수 있다
# 다양한 형 변환
df['date'].astype(int)
df['date'].astype(float)
df['date'].astype('category')
2. str()
파이썬 내장함수
a = "Life is too short"
str(a)
# 다양한 형 변환
int(x)
float(x)str()과 repr()의 차이?
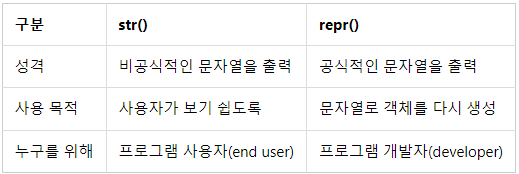
출력의 차이 : str()은 문자열 그대로 반환하지만 repr()은 " ' ' " 형태로 작은 따옴표로 한 번 더 감싸서 반환한다.
glob
정규표현식을 사용해 파일을 검색할 수 있는 모듈
from glob import glob
glob("seoul*.csv")
일부 데이터 보기
df.head()
# 첫 5개 데이터 출력이 디폴트
df.tail()
# 끝 5개 데이터 출력이 디폴트
df.sample()
# 임의의 1개 데이터 출력이 디폴트, 개수 지정 가능
중복 제거하기
df.drop_duplicates()
# df의 중복 데이터를 제거해라
df.duplicated()
# 시리즈 형태로 출력, 중복일 때 True로 나온다
df[df.duplicated()]
# 아무런 결과 데이터가 나오지 않으면 중복이 없다는 뜻이다
인덱스 값 설정하기
#1 df행 갯수와 고유값 갯수가 일치하는지 확인
df.shape
df['연번'].nunique()
#2 고유값을 인덱스로 설정
df = df.set_index('연번')
DataFrame 데이터 정렬하기
#1 인덱스로 정렬
df.sort_index() #기본 오름차순
df.sort_index(ascending=False) #내림차순
#2 값으로 정렬
df.sort_values(by='연번') #기본 오름차순
# by='연번' 값을 기준으로 정렬하기 때문에 기준이 되는 컬럼을 설정해줘야 한다
df.sort_values(by=['연번','환자'])
# by=['연번','환자'] 복수의 기준을 설정하고 싶으면 리스트[ ]로 복수의 컬럼명을 감싼다
df.sort_values(by='연번', ascending=False) #내림차순
Pandas Attributes
# (행, 열)
df.shape
# 컬럼별 데이터 타입
df.dtypes
#행 인덱스 확인
df.index
#열 인덱스 확인
df.columns
기술통계와 데이터 요약
# 기술통계
df.describe()
df.describe(include="object") #문자 데이터에 대한 기술통계
# include="O"라고 써도 됨
# 데이터 요약
df.info()
# df의 모든 정보(컬럼, Non-Null Count, Dtype, 행 개수, 메모리 사용량 등)를 보여준다
결측치 보기
1) 코드 형태
df.isnull().sum() # 컬럼별 결측치 개수 합을 시리즈 형태로 보여준다
df.isnull().mean() # 컬럼별 결측치 비율을 시리즈 형태로 보여준다
df.isnull().mean() * 100 # 컬럼별 결측치 비율의 백분위를 시리즈 형태로 보여준다
df.isna().mean * 100 # 같은 기능, isnull은 isna의 별칭이라고 한다
2) 결측치 시각화
sns.heatmap(df.isnull(), cmap='gray')
# heatmap으로 시각화했을 때 결측치가 뚜렷하게 보인다
시간/날짜 데이터 타입 변경하기
df['확진일'] = pd.to_datetime(df['확진일'])
# pd.to_datetime() ( )안에 지정한 시간/날짜 컬럼을 datetime64형식으로 변환한다
datetime64자료형을 string으로 재변환하고 싶다면
.astype(str)
파생변수 만들기
1. 연, 월, 일, 요일 만들기
# dt accessor사용
df['연도'] = df['확진일'].dt.year # 년year
df["월"] = df['확진일'].dt.month # 월month
df["일"] = df['확진일'].dt.day # 일day
df["요일"] = df['확진일'].dt.dayofweek # 요일dayofweek
# .dt.dayofweek는 월~일이 0~6으로 반환돼 전처리 추가가 필요하다(3. 요일 한글로 만들기 참고)
용례 판다스 공식 문서 참고
https://pandas.pydata.org/docs/reference/api/pandas.Series.dt.html
pandas.Series.dt — pandas 1.5.0 documentation
Accessor object for datetimelike properties of the Series values. Examples >>> seconds_series = pd.Series(pd.date_range("2000-01-01", periods=3, freq="s")) >>> seconds_series 0 2000-01-01 00:00:00 1 2000-01-01 00:00:01 2 2000-01-01 00:00:02 dtype: datetime
pandas.pydata.org
시hour, 분minute, 초second, 분기quarter 등 활용 가능
[Pandas] 일자와 시간(dt) 처리법
Pandas를 이용하여 일자와 시간을 처리하는 방법에 대해서 알아보겠습니다. Pandas에서 지원하는 일자시...
blog.naver.com
2. 연도-월 만들기
# 방법1 : astype(str)로 string타입으로 형 변환, 문자열끼리 연결
df["연도월"] = df['연도'].astype(str)+'-'+df['월'].astype(str)
# .astype(str) str타입으로 형 변환
# + 문자열끼리는 연산 가능
# 방법2 : 문자열 슬라이싱으로 만들기(추천)
df["연도월"] = df['확진일'].astype(str).str[:7]
# .astype(str) str타입으로 형 변환
# .str[:7] 7번째 문자열까지 슬라이싱(yyyy-mm-dd형태에서)
3. 요일 한글로 만들기
# 방법1 : 함수 생성 및 Series의 map 메서드 사용
def find_dayofweek(day_no):
dayofweek = '월화수목금토일' # 새로운 변수를 만들어 월~일을 문자열로 저장
return dayofweek[day_no] #숫자를 입력하면 dayofweek에 대한 문자열 슬라이싱으로 일치하는 문자열 반환
df["요일명"] = df['요일'].map(find_dayofweek)
# map() 리스트의 요소를 지정된 함수로 처리해주는 함수. 원본 리스트를 변경하지 않고 새 리스트를 생성
# 방법2 : 익명함수 lambda로 요일명 컬럼에 바로 저장
df['요일명'] = df['요일'].map(lambda x : "월화수목금토일"[x])
# 문자열의 각 요소에 대해 df['요일']의 값(0~6)과 문자열 인덱스 결과(0~6 : 월~일)가 맵핑된다
기타
BI툴의 장단점
장) 방대한 데이터 효율적으로 시각화, 다양한 그래프, 보기 좋은 시각화
단) 비용 부담, 원하는 대로 커스터마이징하는데 한계
Q. 방대한 데이터를 시각화할 때 속도를 개선하는 방법?
→샘플링해서 사용하기, 범주화해서 구간 만들기, 미리 대표값을 계산하고 난 뒤(그래프 내부 계산X) 시각화하기
-판다스, 씨본, 플롯리 중 조은님은 판다스를 가장 선호하신다. 속도 이슈가 가장 적어서(느린 렌더링 방지 등)
-파이썬의 특징: 세미콜론(;)을 잘 쓰지 않는다
-야크 쉐이빙: 어떤 목적을 달성하기 위해 원래 목적과 전혀 상관없는 일들을 계속해야 하며 그중 마지막 작업을 의미 → 문제를 해결하려고 하다가 다른 길로 빠지게 된다. 즉 본래 목적을 반드시 기억해야 한다.
출처) 멋쟁이 사자처럼 AI스쿨 7기 박조은 강사님 강의자료



